Imagine an AI that doesn't just read text or recognize images separately, but understands them together like humans do. An AI that can look at a photo and describe what's happening, listen to a podcast and generate relevant images, or watch a video and answer complex questions about it. This isn't science fiction anymore. This is multimodal AI, and it's fundamentally changing how machines understand our world.
Traditional AI systems work with one type of data at a time. A language model processes text, a computer vision system analyzes images, and a speech recognition system handles audio. But humans don't experience the world this way. We simultaneously process what we see, hear, read, and feel to form complete understanding. Multimodal AI brings machines closer to this human-like comprehension by combining multiple data types into unified intelligence.
The rise of multimodal AI models like GPT-4 Vision, Google’s Gemini, and Meta’s ImageBind represents a quantum leap in artificial intelligence capabilities. These systems don't just process different data types. They understand the relationships between them, creating richer, more contextual intelligence that opens possibilities previously impossible with single-modal AI.
Multimodal AI refers to artificial intelligence systems that can process, analyze, and understand multiple types of data simultaneously, including text, images, video, audio, and even sensor data. Unlike traditional unimodal AI that specializes in one data type, multimodal systems integrate information from various sources to create comprehensive understanding.
Think about how you understand a movie. You're not just watching images or listening to dialogue separately. Your brain seamlessly combines visual scenes, spoken words, background music, and sound effects to grasp the story, emotions, and meaning. Multimodal AI aims to replicate this integrated processing, allowing machines to develop holistic understanding from diverse information sources.
The power of multimodal AI lies in cross-modal learning, where insights from one data type enhance understanding of another. A multimodal model that sees a picture of a beach while reading the word “vacation” develops stronger associations than systems processing each element separately. This data fusion creates more robust, context-aware AI that handles real-world complexity better than specialized single-purpose systems.
Multimodal machine learning represents a significant evolution in AI architecture. Instead of training separate models for different tasks and trying to connect them afterward, multimodal AI models learn representations that work across all data types simultaneously. This unified approach enables multimodal deep learning systems to discover patterns and relationships invisible to single-modal systems.
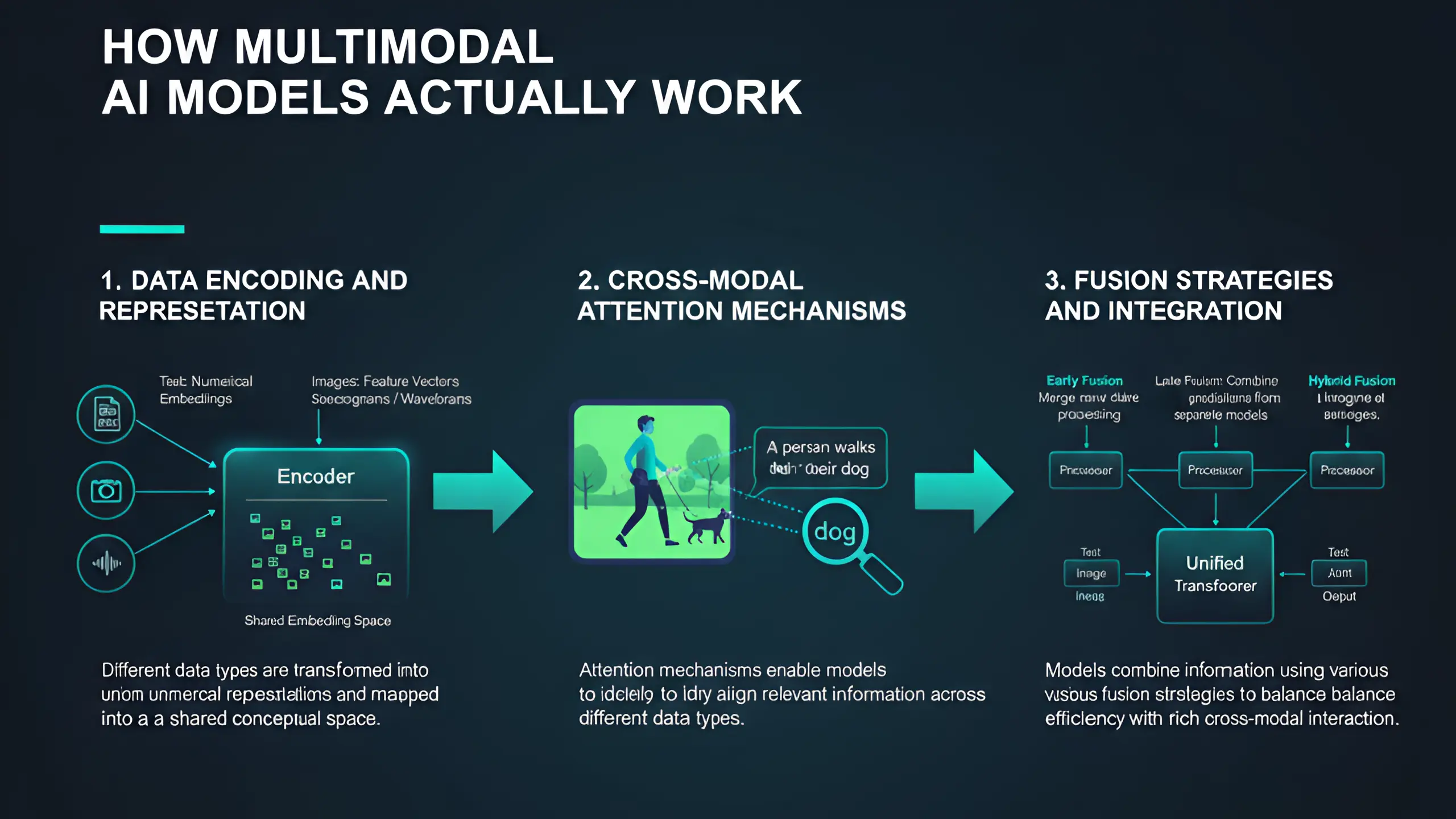
Multimodal AI begins by converting different data types into formats the system can process together. Text gets transformed into numerical embeddings, images become feature vectors, and audio converts into spectrograms or waveform representations. The challenge isn't just encoding each data type, but creating representations that allow meaningful comparison and integration across modalities.
Advanced multimodal models use transformer architectures that excel at finding relationships within and between data types. These neural networks learn to map different inputs into a shared embedding space where similar concepts cluster together regardless of their original format. A photo of a cat, the word “cat,” and the sound of meowing would all map to nearby points in this multimodal representation space.
The breakthrough enabling modern multimodal AI is the attention mechanism that allows models to focus on relevant information across different data types. When processing an image with a text caption, multimodal attention helps the system identify which parts of the image relate to specific words. This cross-modal alignment creates understanding that goes beyond what each modality provides independently.
Vision-language models use attention to ground language in visual reality. When you ask “What color is the car in the image?”, the model uses cross-modal attention to locate the car visually, extract its color information, and generate an appropriate text response. This seamless translation between modalities defines multimodal AI’s power.
Multimodal fusion refers to how systems combine information from different sources. Early fusion merges raw data before processing, late fusion combines predictions from separate models, and hybrid fusion integrates at multiple stages. Modern multimodal AI models typically use hybrid approaches that balance computational efficiency with rich cross-modal interaction.
The fusion architecture significantly impacts model performance. Some multimodal systems process each data type through specialized encoders before combining in a shared decoder. Others use unified transformers that process all modalities simultaneously. The choice depends on the specific application and the types of cross-modal reasoning required.
OpenAI’s GPT-4 Vision represents one of the most capable multimodal AI models available today. This vision-language model seamlessly processes both text and images, answering questions about photos, analyzing charts and diagrams, reading handwritten text, and generating insights that require understanding visual and textual information together.
GPT-4o (the “o” stands for “omni”) extends these capabilities further, processing text, images, audio, and video in real-time. This multimodal model can have voice conversations while looking at what you're showing it, creating truly interactive experiences that feel remarkably human. The model's ability to maintain context across modalities makes it invaluable for complex tasks requiring integrated understanding.
Google’s Gemini model was designed as multimodal from the ground up, rather than combining separate systems. This native multimodal architecture processes text, code, audio, images, and video with exceptional flexibility. Gemini excels at tasks requiring reasoning across modalities, like analyzing video content, understanding complex documents with images, and generating code from visual mockups.
The Gemini family includes different sizes optimized for various applications, from lightweight models for mobile devices to powerful versions handling the most demanding multimodal tasks. This scalability makes multimodal AI accessible across different computing environments and use cases.
CLIP (Contrastive Language-Image Pre-training) revolutionized how we think about vision-language models. Rather than training on labeled images, CLIP learned from 400 million image-text pairs scraped from the internet, developing understanding of visual concepts through natural language descriptions. This multimodal learning approach enables CLIP to recognize objects and scenes it was never explicitly trained to identify.
CLIP’s impact extends beyond its own capabilities. The model's architecture and training methodology influenced countless subsequent multimodal AI models. Its embedding space where images and text share meaning has become foundational for applications from image search to content moderation.
ImageBind from Meta represents an ambitious step toward truly universal multimodal AI. This model learns joint embeddings across six modalities: images, video, text, audio, depth, and thermal data. The remarkable aspect is that ImageBind can understand relationships between modalities it has never seen paired together during training, demonstrating emergent cross-modal capabilities.
For example, ImageBind can associate the sound of ocean waves with beach images even if it never encountered that specific pairing during training. This zero-shot cross-modal understanding suggests paths toward AI that comprehends our world as holistically as humans do.
DeepMind’s Flamingo specializes in few-shot learning across modalities, requiring minimal examples to perform new tasks. This visual-language model can answer questions about images, caption photos, and engage in visual dialogue with remarkable sample efficiency. Flamingo’s architecture demonstrates how multimodal AI can be both powerful and flexible.
Modern multimodal AI examples include systems that provide detailed, contextual descriptions of images. Unlike early computer vision that simply labeled objects, multimodal models generate natural language descriptions capturing scenes, actions, emotions, and context. These systems help visually impaired users understand photos, enable better image search, and power content creation tools.
A multimodal AI analyzing a photo doesn't just identify “dog, park, person.” It might describe “A golden retriever joyfully catching a frisbee in a sunny park while its owner watches and smiles.” This narrative understanding requires integrating visual recognition with language generation and contextual reasoning.
Visual question answering (VQA) represents a compelling multimodal AI application where systems answer natural language questions about images. Users can ask “How many people are wearing red?” or “What time of day is this photo taken?” and the multimodal model analyzes the image and generates accurate text responses.
These VQA systems demonstrate genuine cross-modal reasoning, requiring the model to ground language queries in visual information, perform complex visual analysis, and articulate findings in natural language. Applications range from accessibility tools to educational platforms and interactive customer service.
Multimodal AI excels at understanding video content by processing visual frames, audio tracks, and any embedded text simultaneously. These systems can summarize hour-long videos into key points, identify specific moments when certain topics are discussed, and answer detailed questions about video content without humans watching everything.
Content creators use multimodal video AI to automatically generate descriptions, timestamps, and tags. Educational platforms employ these tools to create searchable video libraries. Security applications use multimodal analysis to detect and understand events in surveillance footage.
Complex documents containing text, images, charts, and tables challenge traditional AI systems. Multimodal AI models process these documents holistically, understanding how textual content relates to visual elements. This capability enables automated document analysis for legal contracts, financial reports, scientific papers, and medical records.
A multimodal system analyzing a medical report doesn't just read the text. It examines embedded X-rays, relates written diagnoses to visual evidence, and extracts structured information from complex layouts. This comprehensive document understanding dramatically improves accuracy over text-only processing.
Multimodal AI that combines audio and video understanding enables applications like automatic video captioning, speaker identification in conversations, and audio-visual speech recognition that works even in noisy environments. These systems use visual lip movements to enhance audio understanding and vice versa, achieving robustness impossible with single-modal approaches.
Entertainment applications use audio-visual AI to automatically edit videos, synchronize subtitles, and generate special effects that respond to both sound and imagery. Accessibility tools leverage these multimodal models to provide richer experiences for users with hearing or vision impairments.
Multimodal AI in healthcare integrates medical images, patient records, genetic data, and clinical notes to provide comprehensive diagnostic support. A system analyzing a potential cancer case might examine CT scans, review pathology reports, consider patient history, and compare against thousands of similar cases to provide insights no single-modal system could offer.
Medical multimodal models help radiologists by correlating imaging findings with lab results and symptoms. They assist pathologists by combining tissue images with molecular data. These applications improve diagnostic accuracy while reducing the cognitive burden on healthcare professionals managing increasingly complex patient information.
Self-driving cars represent perhaps the most demanding multimodal AI application, requiring integration of cameras, LiDAR, radar, GPS, and inertial sensors. Multimodal fusion creates comprehensive environmental understanding that enables safe navigation. The vehicle must simultaneously process visual road conditions, radar-detected obstacles, GPS location data, and sensor information about vehicle dynamics.
Robotics applications similarly rely on multimodal AI to perceive and interact with physical environments. Robots combine visual information, tactile feedback, audio cues, and proprioceptive data to perform complex manipulation tasks. This multimodal perception enables robots to handle objects with appropriate force, navigate cluttered spaces, and respond to human instructions.
Creative industries increasingly employ multimodal AI to generate and edit content. Systems create images from text descriptions, generate video from scripts, produce music that matches visual moods, and edit multimedia presentations automatically. These multimodal AI tools augment human creativity rather than replacing it, handling technical execution while creators focus on vision and strategy.
At Secuodsoft, we're an AI-first driven solution company specializing in artificial intelligence and machine learning implementations for businesses. As technologies like multimodal AI continue to advance, we help organizations understand and leverage these innovations to solve real business problems. Our development team works with clients to build custom AI solutions, whether that's computer vision systems for visual recognition, natural language processing for text analysis, or integrated approaches that combine multiple AI capabilities. We stay at the cutting edge of AI technology, ensuring our clients can take advantage of the latest advancements like multimodal models to drive business value and competitive differentiation.
Multimodal AI dramatically improves accessibility tools for people with disabilities. Vision-language models describe visual content for blind users, audio-visual systems enhance speech recognition for deaf users, and multimodal interfaces provide multiple interaction methods accommodating different needs and preferences.
Modern accessibility applications go beyond simple description. They provide rich, contextual understanding that makes digital content truly accessible. A multimodal AI doesn't just say “image of people.” It describes “Three colleagues collaborating around a laptop in a bright office, pointing at the screen while discussing ideas.” This detail transforms accessibility from basic functionality to genuine inclusion.
Online shopping benefits enormously from multimodal AI applications. Visual search allows customers to find products by uploading photos. Multimodal recommendation systems consider browsing history, purchase patterns, product images, and customer reviews to suggest relevant items. Virtual try-on experiences combine customer photos with product images to show how items look.
Retailers use multimodal AI to analyze customer behavior across touchpoints, combining in-store video, online clickstreams, purchase data, and customer service interactions. This integrated understanding enables personalized experiences and optimized operations that single-modal analytics cannot achieve.
Multimodal AI in education creates adaptive learning experiences that combine text, images, video, and interactive elements tailored to individual students. These systems assess student understanding through multiple modalities, recognizing when students struggle by analyzing facial expressions, voice patterns, and interaction behaviors alongside traditional performance metrics.
Educational multimodal AI platforms generate personalized content, automatically creating explanations with appropriate visualizations, examples, and difficulty levels. They answer student questions by searching across textbooks, videos, and supplementary materials, presenting information in formats best suited to each learner.
Building effective multimodal AI models requires careful architecture design. Researchers use neural architecture search to discover optimal configurations for combining different data types. The challenge involves balancing model complexity with computational efficiency while ensuring each modality receives appropriate representation in the unified system.
Modern multimodal architectures often employ modular designs where specialized encoders process each data type before integration in shared layers. This approach allows leveraging domain-specific processing while maintaining the benefits of cross-modal learning. Transformer-based architectures have proven particularly effective, with their attention mechanisms naturally suited to relating information across modalities.
Training multimodal AI presents unique challenges compared to single-modal systems. Models require aligned data where different modalities correspond to the same concept or instance. Collecting such multimodal datasets is expensive and time-consuming, driving research into self-supervised learning methods that learn from naturally co-occurring data like images with captions or videos with audio.
Contrastive learning has emerged as a powerful training strategy for multimodal models. By learning to distinguish matching and non-matching pairs across modalities, systems develop robust cross-modal representations without requiring explicit labels. This approach enables training on massive internet-scale datasets that would be impractical to manually annotate.
Real-world multimodal AI applications often face scenarios where some modalities are missing or of poor quality. Robust multimodal systems must handle these situations gracefully, adapting to available information without catastrophic performance degradation. Techniques like modality dropout during training prepare models to function even when certain inputs are unavailable.
Modality fusion strategies must also account for different information rates and qualities across data types. Video provides information at 30 frames per second, while text might update only occasionally. Multimodal architectures use temporal alignment and attention mechanisms to appropriately weight contributions from each modality based on their reliability and relevance.
Multimodal AI achieves deeper understanding by combining complementary information from different sources. Visual information provides spatial and appearance details, text adds semantic meaning and abstract concepts, and audio contributes temporal dynamics and emotional cues. This multi-perspective understanding creates more robust and accurate AI that handles ambiguity better than single-modal systems.
When a multimodal model encounters unfamiliar situations, it can leverage different modalities to build understanding. If visual information is unclear, textual context might clarify. If language is ambiguous, visual evidence can disambiguate. This cross-modal verification improves reliability in real-world deployment.
Systems processing multiple data types demonstrate greater robustness to noise and errors. If one modality contains corrupted or missing information, multimodal AI compensates using other sources. This redundancy makes multimodal systems more reliable in challenging real-world conditions where perfect data isn't guaranteed.
Multimodal learning also improves model generalization. By learning relationships between modalities, AI develops more fundamental understanding of concepts rather than memorizing superficial patterns in single data types. This deeper learning translates to better performance on novel situations and edge cases.
Humans communicate multimodally, combining speech, gestures, facial expressions, and shared visual context. Multimodal AI enables more natural interfaces that understand this rich communication. Users can point at objects while speaking, show documents during conversations, or use drawings to clarify explanations. These multimodal interactions feel more intuitive and efficient than traditional single-channel interfaces.
Conversational AI benefits tremendously from multimodality. Virtual assistants that see what users see, hear what they hear, and understand textual context provide dramatically better experiences than voice-only or text-only systems. This natural interaction paradigm makes AI accessible to users who struggle with traditional interfaces.
Multimodal AI models demand significant computational resources for training and inference. Processing multiple data types simultaneously requires more memory, processing power, and energy than single-modal systems. Large vision-language models contain billions of parameters and require expensive GPU infrastructure, limiting accessibility for smaller organizations and edge deployment scenarios.
Research into efficient multimodal architectures, model compression, and knowledge distillation aims to make these systems more practical. Lightweight multimodal models trade some capability for dramatically reduced resource requirements, enabling deployment on mobile devices and embedded systems.
Effective multimodal learning requires well-aligned data where different modalities correspond meaningfully. Misaligned or weakly related data degrades model performance. Collecting and curating high-quality multimodal datasets is expensive and time-consuming, limiting the types of multimodal AI that can be developed.
Data quality varies across modalities, with some sources more reliable or informative than others. Multimodal systems must learn to appropriately weight different inputs, recognizing when one modality should dominate decision-making and when multiple sources should contribute equally.
Understanding why multimodal AI makes specific decisions proves challenging. When systems integrate information from multiple sources through complex neural networks, tracing decision logic becomes difficult. This black box problem concerns users deploying multimodal AI in high-stakes applications like healthcare or autonomous vehicles where transparency matters.
Research into explainable multimodal AI develops techniques for visualizing cross-modal attention, identifying which inputs influenced decisions, and generating human-understandable rationales. These interpretability tools build trust and enable human oversight of multimodal systems.
The trajectory of multimodal AI points toward increasingly sophisticated and capable systems. Future models will process more modalities including touch, smell, and proprioception, approaching human-like sensory integration. Unified models that seamlessly handle any combination of inputs and outputs will replace today's specialized systems.
Embodied AI represents an exciting frontier where multimodal systems control physical robots that learn from rich sensory experiences. These agents will develop genuine understanding through interaction with the physical world, much like humans learn through multisensory exploration.
Personalized multimodal AI will adapt to individual users, learning their communication styles, preferences, and contexts. These systems will provide truly customized experiences that feel natural and intuitive, understanding not just what users say but how they prefer to interact.
Real-time multimodal AI will enable applications currently impossible due to latency constraints. Imagine simultaneous translation that preserves gestures and facial expressions, or augmented reality that seamlessly blends digital and physical information with zero lag. These capabilities will transform how we work, learn, and communicate.
Multimodal AI represents a fundamental shift in artificial intelligence, moving from narrow specialists to systems with comprehensive, human-like understanding. The ability to process and integrate multiple data types creates AI that's more capable, more robust, and more aligned with how humans naturally perceive and interact with the world.
The multimodal AI models emerging today are just the beginning. As research advances and computational resources grow, we'll see increasingly sophisticated systems that blur the lines between different AI capabilities. The future isn't separate systems for vision, language, and audio, but unified intelligence that seamlessly handles all modalities.
Organizations adopting multimodal AI now position themselves at the forefront of this transformation. Whether improving customer experiences, enhancing product capabilities, or creating entirely new services, multimodal AI offers opportunities for innovation and competitive advantage that single-modal systems simply cannot match.
The multimodal AI revolution is here, and its impact will only grow. The question isn't whether to embrace these technologies, but how quickly you can leverage them to transform your capabilities and create experiences that were previously impossible.
Copyright ©2026 Secuodsoft. All rights reserved.